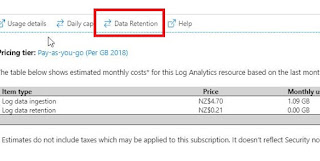
Sometimes when things are not so clear, and it suddenly turns mysterious when another person say else. All you ever get is a huge mess. This is one of those cases Operation Tab In this tab, you get to see "What and how long an operations are running on my server" Operation times give you how long a spike last. What is the peak operation time happened on the server. Just underneath the "Operation time", you can sub-divide by Request, CPU, Available Memory, Storage. The story it is telling is, during those time when the spike occurs, how is my resources holding up? Does memory got sucked out and is the CPU reaching certain limit (since it is showing a number like 0, 1,2) i am thinking it means, average limit between available CPU. The distribution chart, shows where percentage of operations lies. In my case, 50% of the time, there are over 100 request processed within 64 miliseconds, 90% of the time, under 10 request served within 6.8 seconds windo...